Producers and Consumers
What are Producers?
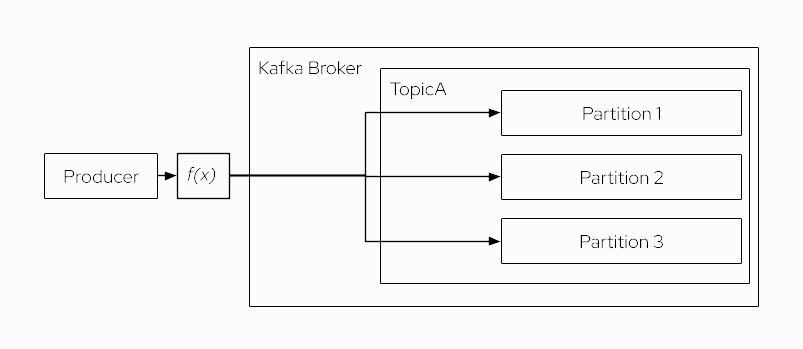
Producers publish messages by appending to the end of a topic partition.
By default, if a message contains a key (i.e. the key is NOT null), the hashed value of the key is used to decide in which partition the message is stored. If there is a specific key set for the message, then the producer’s default hash partitioning guarantees that long as no new partitions are added, all messages with the same key will be stored in the same topic partition. This behaviour is essential whenever you want to ensure that message for one and the same key are consumed and processed in order from the same topic partition.
If the key is null, the producer behaves differently according to the Kafka version:
-
up to Kafka 2.3: a round-robin partitioner is used to balance the messages across all partitions
-
Kafka 2.4 or newer: a sticky partitioner is used which leads to larger batches and reduced latency and is particularly beneficial for very high throughput scenarios
You can also implement your own custom partitioning strategy to store messages in a specific partition following any kind of business rule.
What are Consumers?
Each message published to a topic is delivered to a consumer that is subscribed to that topic.
A consumer can read data from any position of the partition, and internally the position is stored as a pointer called offset. In most of the cases, a consumer advances its offset linearly, but it could be in any order, or starting from any given position.
Each consumer belongs to a consumer group. A consumer group may consist of multiple consumer instances. This is the reason why a consumer group can be both, fault tolerant and scalable. If one of several consumer instances in a group dies, the topic partitions are reassigned to other consumer instances such that the remaining ones continue to process messages form all partitions. If a consumer group contains more than one consumer instance, each consumer will only receive messages from a subset of the partitions. When a consumer group only contains one consumer instance, this consumer is responsible for processing all messages of all topic partitions.
Message consumption can be parallelized in a consumer group by adding more consumer instances to the group, up to the number of a topic’s partitions. Concretely, if a topic e.g. has 8 partitions, a consumer group can support up to 8 consumer instances which all consume in parallel, each from 1 topic partition.
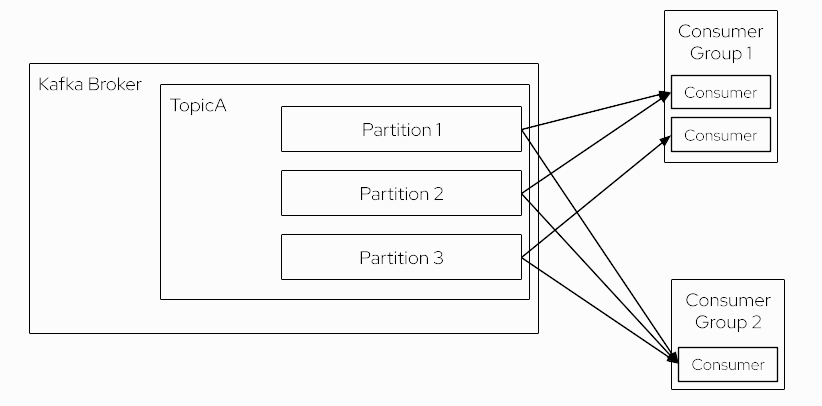
| If you add more consumers in a consumer group than the number of partitions for a topic, then they will stay in an idle state, without getting any message. |
As you can see what is registered to a topic is the consumer group and not the consumer instance. The consumer instance is "subscribed" to (a subset of) topic partitions.
Consume and Produce Messages
Before digging into how to produce and consume data from Java, let’s see how to use kcat to do it.
kcat is a great tool for these use cases, and it is one of the most popular CLI tools to work with data in Kafka topics.
Consuming messages with kcat
Open a new terminal, terminal 1, and run the following command:
kcat -b localhost:29092 -t songs -C -K:docker run --rm -it --network=kafka-tutorial edenhill/kcat:1.7.1 kcat -b kafka:9092 -t songs -C -K:% Reached end of topic songs [0] at offset 0Producing messages with kcat
Open a new terminal, terminal 2, and create a new file named initial_songs with the content shown below:
1: {"id": 1, "name": "The Ecstasy of Gold", "author":"Ennio Morricone", "op":"ADD"}
2: {"id": 2, "name": "Still Loving you", "author":"Scorpions", "op":"ADD"}Then use kcat to produce a new message to the songs topic for each line in the initial_songs file. Note that the number before the colon : is taken as the message key.
kcat -b localhost:29092 -t songs -P -l -K: initial_songsdocker run --rm -it --network=kafka-tutorial -v $(pwd)/documentation/modules/ROOT/examples/initial_songs.json:/home/initial_songs edenhill/kcat:1.7.1 kcat -b kafka:9092 -t songs -P -l -K: /home/initial_songsSwitch back to terminal 1 where you are running kcat as a consumer.
You’ve defined this at Consuming messages with kcat section.
Now the output of the terminal has been updated showing the consumed messages:
1t {"id": 1, "name": "The Ecstasy of Gold", "author":"Ennio Morricone", "op":"ADD"}
2t {"id": 2, "name": "Still Loving you", "author":"Scorpions", "op":"ADD"}
% Reached end of topic songs [0] at offset 2Notice that the offset of this consumer has been updated to 2, as the two first records have been consumed from the topic.
Playing with Offsets
A producer always produces content at the end of a topic, meanwhile, a consumer can consume from any offset.
Still on terminal 1, stop the kcat process by typing Ctrl+C.
Start kcat once more with the same command as further above for consuming from the songs topic again:
kcat -b localhost:29092 -t songs -C -K:docker run --rm -it --network=kafka-tutorial edenhill/kcat:1.7.1 kcat -b kafka:9092 -t songs -C -K:1: {"id": 1, "name": "The Ecstasy of Gold", "author":"Ennio Morricone", "op":"ADD"}
2: {"id": 2, "name": "Still Loving you", "author":"Scorpions", "op":"ADD"}
% Reached end of topic songs [0] at offset 2Notice that the whole topic with all messages is consumed again. This is happening because by default kcat is reading from the beginning of the topic (i.e. the oldest message that is still stored). But you can change that anytime.
Stop again kcat process by typing Ctrl+C.
Now start kcat again with the -o flag and the offset number 1.
kcat -b localhost:29092 -t songs -o 1 -C -K:docker run --rm -it --network=kafka-tutorial edenhill/kcat:1.7.1 kcat -b kafka:9092 -t songs -o 1 -C -K:2: {"id": 2, "name": "Still Loving you", "author":"Scorpions", "op":"ADD"}
% Reached end of topic songs [0] at offset 2This time, the initial offset was explicitly set to 1 i.e. the consumption was beginning at the 2nd message.
Changing Retention
By default, Kafka retains messages in a topic for 168 hours (7 days). But retention time can be changed, so let’s modify it to e.g. 1 minute.
You can use kafka-topic.sh tool to change the retention time of a topic.
Open a third terminal:
This tool is bundled with the Kafka container image, so let’s exec a bash terminal inside the running Kafka container.
docker exec -it $(docker ps -q --filter "label=com.docker.compose.service=kafka") /bin/bashInside the container’s bash run:
./bin/kafka-configs.sh --bootstrap-server kafka:9092 --entity-type topics --entity-name songs --alter --add-config retention.ms=60000Completed updating config for topic songs.And check that it has been configured correctly:
./bin/kafka-topics.sh --describe --bootstrap-server kafka:9092 --topic songsTopic: songs TopicId: h2aw0peOTHuWYleUpZxj-Q PartitionCount: 1 ReplicationFactor: 1 Configs: retention.ms=60000
Topic: songs Partition: 0 Leader: 0 Replicas: 0 Isr: 0In your other terminal, stop the kcat process by typing Ctrl+C and wait for ~60 seconds (ie sleep 60). After the time has passed run the kcat in consumer mode again:
kcat -b localhost:29092 -t songs -C -K:docker run --rm -it --network=kafka-tutorial edenhill/kcat:1.7.1 kcat -b kafka:9092 -t songs -C -K:% Reached end of topic songs [0] at offset 2The important part is the last line, notice that it returns no messages, but the offset is 2. The reason is that the messages are expired and deleted from the topic, but the offset has its retention period. By default, this retention period is 1 week, so although there is no data, the current offset for a consumer is '2'.
Also note, that Kafka brokers have a configuration for log.retention.check.interval.ms and this setting must be lower than/equal to a topic’s retention.ms, otherwise cleaning out offsets will not be effective "immeadiately" but only after the log cleaner ran to do its job. In other words, it may take longer (up to log.retention.check.interval.ms) before you can actually observe the data retention happening in the corresponding Kafka topic.
Change retention time to the default one by running in the third terminal (the one you did docker exec), the following command:
./bin/kafka-configs.sh --bootstrap-server kafka:9092 --entity-type topics --entity-name songs --alter --delete-config retention.msCompleted updating config for topic songs.Deleting Topic Content
You can also use kafka-topic.sh tool to delete the content of a topic manually.
This tool is bundled with the Kafka container image, so let’s exec a bash terminal inside the running Kafka container.
docker exec -it $(docker ps -q --filter "label=com.docker.compose.service=kafka") /bin/bashInside the container run:
./bin/kafka-topics.sh --delete --bootstrap-server kafka:9092 --topic songsNow that the topic is deleted, you can run the exit command:
exit